
A FAT12 file system's directory consists of a number of 32 byte long entries. The first 11 characters of each entry are the file name (8 characters) and file type (3 characters).
Mounted as a -t msdos in Linux it looks like this.

On the disk, as seen in a hex editor, it looks like this.
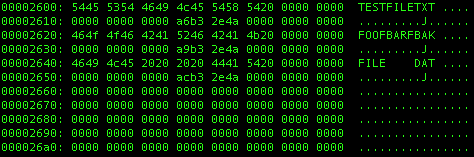
Note that file names shorter than 8 characters are actually 8 characters long with the missing characters filled with spaces (ASCII 0x20).
Returning to the existing boot loader, with the variable names updated because I felt like it. This is the new beginning of the boot sector.
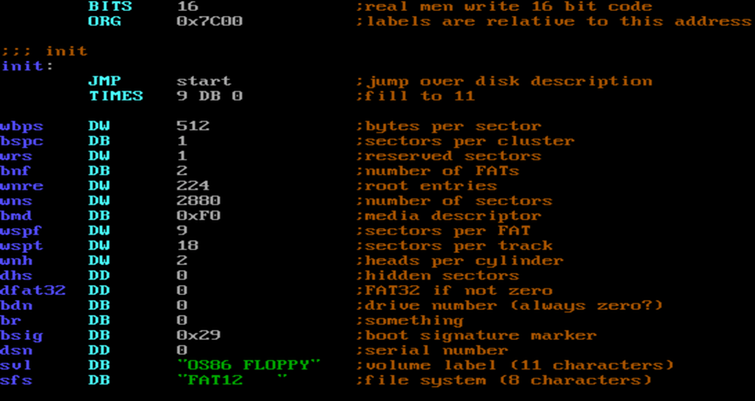
As noted in earlier blog entries this code is loaded at address 0x7C00. The root directory has to be loaded somewhere too (and later the FAT). There is also need for a stack segment (which here starts at 0x6C00 some 4 KB before the code).
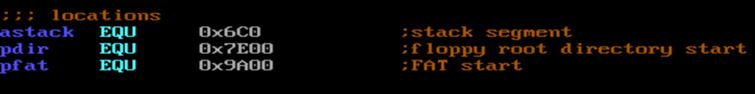
Remember that segment registers are extended by a nybble (half a byte). Hence 0x6C0 in a segment register equals the segment base address 0x6C00. (In order not to be confused I start the names of offsets with a "p" and the names of segment addresses with "a".)
The boot loader main routine configures the segment registers (code = data = extra, stack at 0x6C00) and defines a stack of 4 KB. It then proceeds to print "hello" before calling the loaddir and findfile routines and ending the program with printing "bye" before rotating forever.

The loaddir routine loads the disk's root directory at address 0x7E00. The root directory is 14 sectors long and starts at sector 19.
The IBM 3.5" 1.44 MB floppy disk has 80 tracks and 18 sectors per track. (It also has two sides, if you can believe it.) The fact that the root directory is located right at the beginning of a track and is shorter than the track allows reading it with little calculation and in one move.
Sector 19 is the second sector of the second side of the first track.
Tracks are zero-based. Hence the first track is track 0. This goes into CH.
Sectors are one-based. Hence the second sector is sector 2. Goes into CL.
Disk sides are zero-based. Hence the second side is side 1. Goes into DH.
There is only one drive. Drives are zero-based. Drive 0 goes into DL.
This routine uses hard-coded block addresses. (I think this is appropriate since the geometry of the disk was known when the boot sector was written. It's also easier to write. The routines for calculating logical block addresses from physical addresses and vice versa explained in a previous entry are not being used.)

After loading the root directory at address 0x7E00 each entry needs to be read and compared to the name of the file that needs loading. This is as far as this goes for now.

This routine displays the file name and type it finds when comparing each directory entry with the image file name. (Ultimately it should of course load the file and far jump into the newly loaded code.)
The accumulator (AX) is initialised with 0 to be used as an offset, the counter (CX) with the number of root directory entries (224). The source index (SI) is initialised with the address of the image file name and the destination index is initialised with the address of the root directory in memory (0x7E00).
At this point the loop starts.
The current directory entry is at DI+AX. The relevant part of the entry is the first 11 bytes, the file name (8 bytes) and the file type (3 bytes). This is compared with the image file name. The string comparison is done using a special x86 instruction for string comparisons that uses the SI and DI registers (which are already filled correctly) and the CX register (which therefor has to be saved before and restored after the string comparison). The string comparison is to be done on 11 characters, hence CX is initialised with 11.
If the two 11-character strings are equal, the file is found and its name displayed on the screen. There happens to be a zero following the file name. This is because byte 11 is the attribute byte and there are no attributes set. I am using this fact so I can use my writes routine which prints zero-terminated strings.
When running, it looks like this.
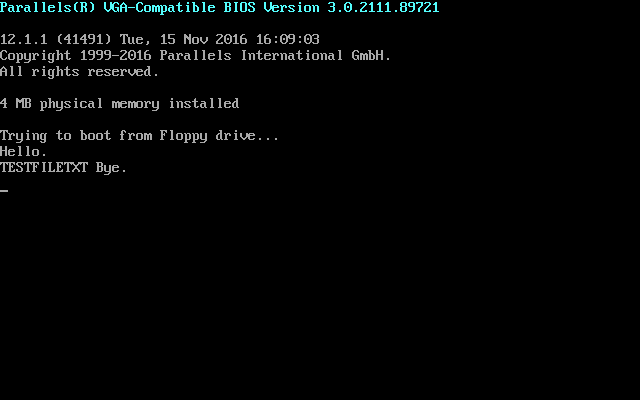
Note that there is no carriage return and line feed following the file name and file type output.
To be continued...